DEML0: Data Engineering for Machine Learning and Data Science Learning Plan
In the Data Engineering for Machine Learning and Data Science Learning Plan, instructor Dr. Prashanth H. Southekal equips participants with key data concepts and skills needed to acquire and enable quality data through practical data engineering techniques for advanced analytics and machine learning initiatives. Each of the four courses in the plan covers an essential topic for organizations seeking to implement such solutions.

In the era of low cost and quick data generation, storage and computation, the smart and intelligent enablement of data offers tremendous value for organizations seeking to implement artificial intelligence and machine learning solutions. However, deriving good insights for measuring and improving business performance is dependent on quality data, including improving the correctness, accuracy, completeness, and relevancy of those data assets. It takes well-executed data engineering techniques to accomplish such tasks.
Measuring the quality of data and being fit-for-purpose brings challenges, causing business analysts and data scientists to struggle to derive reliable insights. In the 4-course Data Engineering for Machine Learning and Data Science Learning Plan, instructor Dr. Prashanth H. Southekal equips participants with the necessary and practical data engineering methods to work through such problems. Acquiring quality data to derive accurate and timely insights takes time, consumes a lot of effort, and is often very expensive. In fact, over 80% of the time, effort, and cost in data analytics projects is in data enablement or data engineering.
In the Data Engineering for Machine Learning and Data Science Learning Plan you will:
- Understand the need for data engineering in machine learning and data science
- Learn the key points and concepts for the data lifecycle, data engineering processes, data transformation, and processing data for analytics
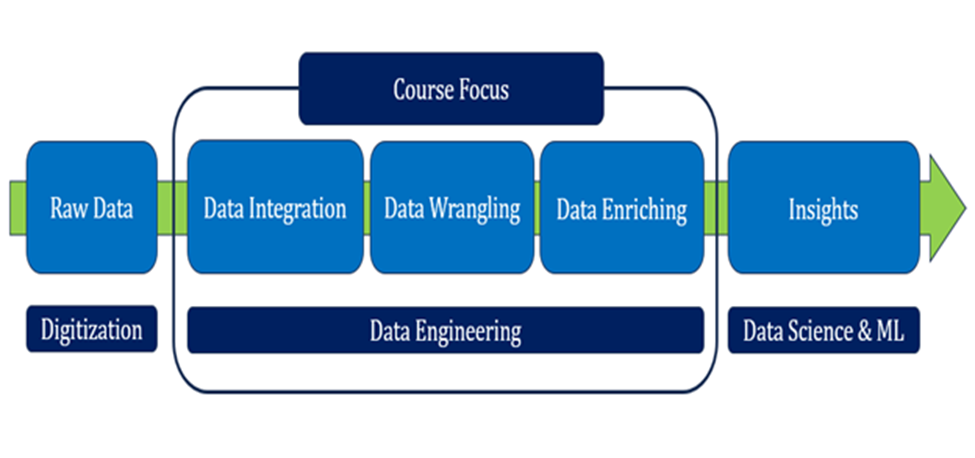
- Learn about data integration, data wrangling, and data enrichment – the key components of data engineering
- Discuss how to apply data wrangling techniques such as: data imputation, numerical analysis, data conversion, and sampling
- Learn data enrichment techniques such as: feature engineering, synthetic data, SPD and TPD integration, and survey analysis
- Understand the importance of governing data, data validation and profiling, and data ethics/risks
- Explore the importance of business data and data quality
The image below is the scope of the course.
Individual Course Price: $99
Learning Plan Price: $336
Learning Plan CEUs: 7.0 hours
Each Course Includes:
- A 46- to 77-minute educational training video
- A 19- to 22-question exam
- “Check for Understanding” quizzes after each course section
- Self-paced and on-demand e-learning
- Unlimited course access
Downloadable documents/resources include:
- 12 Dimensions of Data Quality
- Data Analytics Abbreviations
- Data Science Cheat Sheet
- Types of Variables in Data Science
- Top Algorithms in Data Science
- SQL Cheat Sheet
- Structuring Data from Unstructured Data
Courses within the Data Engineering for Machine Learning and Data Science Learning Plan:
1. Introduction to Data Engineering and Data Enablement
2. Data Wrangling in Data Engineering
3. Data Enrichment in Data Engineering
4. Governing and Managing the Enabled Data
We offer several bulk licensing options for corporate and group use.
Contact us for a follow-up discussion!
Data Engineering for Machine Learning and Data Science Learning Plan
Course 1: Introduction to Data Engineering and Data Enablement
- Introduction to Data Analytics
- Analytics Defined
- Data Lifecycle (DLC) Defined
- Types of Data Analytics – The Data Continuum
- Benefits of Data Analytics
- The Key Question to Ask Oneself
- Data Engineering in Analytics
- Business Data
- Data Needs in Analytics
- Data Availability and Question / Insight Complexity
- Addressing Data Quality
- Data Engineering Defined
- The Key Data Engineering Process
- Data Exploration / Extraction (with SQL)
- Typical Data Engineering Activities
- Why is Analytics Heavy on Data Engineering?
- Business/Data Analyst vs. Data Engineer vs. Data Scientist
- Business Data and Its Types
- Data Defined
- Key Terms
- Types of Business Data
- Business Impact vs. Size
- Four Types of Business Data Types
- Native State and Processed State
- Business Data Based on Storage
- Business Data Based on Integration
- Metadata
- Example of Integrated Business Data
- Business Data Based on Security
- Business Data Based on Analytics
- Why Data Transformation Matters in Analytics
- Processing Data for Analytics
- Business Data Views
- Transactions: The Mainstay of Business Analytics
- Summary of Course 1
Course 2: Data Wrangling in Data Engineering
- Introduction to Data Integration (Part 1 of 3)
- Data Integration
- Data Integration Methods
- Data Integration Method Selection
- Data Wrangling and its Techniques (Part 2 of 3)
- Data Wrangling
- The Importance of Data Wrangling
- Data Wrangling
- Data Wrangling Techniques
- Data Imputation for Missing Values
- Data Imputation on Missing Data
- Missing Data Value Categories
- Missing Data Categories and Solutions
- Data Imputation Methods
- Hot Deck Imputation
- Example
- Cold Deck Imputation
- Example
- Regression Imputation
- Example 1
- Example 2 - Excel
- SLR Output
- Validating the Regression Model
- Using the Regression Model for Prediction
- Example 1
- Hot Deck Imputation
- Interpolation
- Gregory Newton Forward Interpolation Technique
- Newton Forward Interpolation Case Study
- Gregory Newton Backward Interpolation Technique
- Newton Backward Interpolation Case Study
- Lagrange’s Interpolation Technique
- Lagrange’s Technique Case Study
- Gregory Newton Forward Interpolation Technique
- Extrapolation
- Interpolation vs. Extrapolation
- Trend Line (Linear)
- Trend Line
- Trend Line in Correlation
- Trend Line in Function
- Lagrange’s Technique for Data Extrapolation
- Curve Fitting
- Numerical Analysis
- Least Squares Method (LSM)
- LSM for Quadratic Curve Fitting
- LSM for Cubic Curve Fitting
- Data Conversion
- Data Conversion and Transformation
- Data Conversion Example
- Data Standards Case Study
- Data Standards with Noun-Modifier-Attribute (NMA)
- Data Standards with PIDX and UNSPSC Standards
- Data Sampling
- Sample Size (SS)
- Sample Size in Relation to Calgary’s Population
- Getting Sample Random Data Records
- Avoiding Sampling Bias
- Data Imputation for Missing Values
- Summary and Wrap-Up (Part 3 of 3)
- Summary of Course 2
Course 3: Data Enrichment in Data Engineering
- Introduction to Data Enrichment (Part 1 of 3)
- Data Enrichment
- Data Enrichment vs. Data Wrangling
- Importance of Data Enrichment
- Data Enrichment Techniques (Part 2 of 3)
- Data Enrichment Techniques
- Feature Engineering
- Example
- Attribute Construction Steps
- Data Labelling
- Attribute Construction Steps: An Example
- Synthetic Data
- Benefits of Synthetic Data
- Data Clean Room (DCR)
- Application of Synthetic Data
- SPO and TPD Data Integration
- Type of Business Data
- SPD and TPD Data Acquisition
- Data Integration Methods
- Data Integration Method Selection
- Message = Payload Data + Wrapper Data
- Types of Middleware Systems
- Survey Data
- Survey Data
- Survey Design
- Survey Questions vs. Response
- Survey Case Study on PTP Value Chain
- Feature Engineering
- Data Enrichment Techniques
- Summary and Wrap-Up (Part 3 of 3)
- Integrating New Data to Enrich Existing Data
- Step 1: Data Acquisition
- Step 2: Combine Data
- Step 3: Data Validation and Cleansing
- Summary of Course 3
- Integrating New Data to Enrich Existing Data
Course 4: Governing and Managing the Enabled Data
- The Key Data Engineering Process
- Table of Contents: Data Transformation (Part 1 of 5)
- Data Transformation
- Data Normalization
- Data Standardization
- De-Duping
- Data Validation – Integrity and Profiting (Part 2 of 5)
- Data Integrity Validation
- Data Quality Dimensions
- Assessing Data Quality: An Example
- 4 Types of Data Integrity
- Profiling Data
- Normal Distribution (Bell Curve)
- How to Get Normally Distributed Data Set
- Ensemble Methods (Part 3 of 5)
- Ensemble Methods
- Data Engineering Techniques
- Basic Ensemble Techniques
- Quiz
- Data Governance (Part 4 of 5)
- Data Governance
- System of Record (SOR)
- SOR in Analytics
- The Current State of Data Governance
- Data Governance Framework
- Data Governance and Master Data
- Data Governance Implementation Elements (3 Domains)
- Data Democratization vs. Data Protection
- Data Governance Best Practices
- Summary and Wrap-Up (Part 5 of 5)
- The Data Analytics Value Chain
- Data Analytics Fabric
- Module 4 Summary
- Training Wrap-Up
- Summary 1
- Summary 2
- Summary 3
- Summary 4
- Summary 5
Complete All Four Data Engineering for Marching Learning and Data Science Courses
1. DEML1: Introduction to Data Engineering and Data Enablement
required
Deriving accurate and timely insights is dependent on quality data. In this course, instructor Dr. Prashanth H. Southekal provides a solid overview of data and the importance of the data lifecycle, characteristics, and types as well as the key data quality dimensions pertinent to data analytics and data engineering.
View Details2. DEML2: Data Wrangling in Data Engineering
required
Data Wrangling or data cleaning consists of preparing and validating existing data to improve its quality for deriving insights. In this course, instructor Dr. Prashanth H. Southekal covers multiple data wrangling techniques for data engineering.
View Details3. DEML3: Data Enrichment in Data Engineering
required
In this course, instructor Dr. Prashanth H. Southekal explores how data enrichment is used to enhance, refine, and improve the utilization of existing data with other relevant data sets. The goal of data enrichment is to enhance the value of data and be more proactive in its utilization.
View Details4. DEML4: Governing and Managing the Enabled Data
required